Introduction:
- Next-generation sequencing (NGS) is a method of DNA sequencing that allows for the rapid and high-throughput determination of the nucleotide sequence of a DNA molecule.
- It has revolutionized the field of genomics by allowing researchers to analyse the entire genome of an organism or specific regions of interest at a much faster rate and lower cost than traditional Sanger sequencing methods.
- Second-generation sequencing, also known as next-generation sequencing (NGS), is a method of DNA sequencing that was developed in the mid-2000s. It involves parallel sequencing of many DNA molecules at the same time, which allows for the rapid and high-throughput determination of the nucleotide sequence of a DNA molecule.
- NGS technologies use a variety of approaches to sequence DNA, including single-molecule sequencing, clonal amplification sequencing, hybridization-based sequencing, sequencing by synthesis, ion semiconductor sequencing, and nanopore sequencing.
Principle:
- Next-generation sequencing (NGS) is a powerful technology that allows scientists to quickly and accurately sequence DNA or RNA molecules. The principle of NGS is based on the ability to synthesize DNA strands using short, complementary DNA strands (known as “sequencing by synthesis”).
- In NGS, a sample of DNA or RNA is first amplified using polymerase chain reaction (PCR) or another amplification method. The amplified DNA or RNA is then fragmented into small pieces and attached to a solid surface (such as a glass slide or a flow cell).
- Next, the DNA or RNA strands are sequenced using a sequencer. There are several different methods of NGS, each with its own strengths and limitations. Some common methods of NGS include pyrosequencing, Illumina sequencing, Ion Torrent sequencing, single-molecule real-time sequencing (SMRT sequencing), and PacBio sequencing.
- In most NGS methods, the sequencer uses short, complementary DNA strands (known as “sequencing primers”) to synthesize longer DNA strands. As each nucleotide is added to the synthesized DNA strand, it is detected and recorded by the sequencer. This process is repeated until the entire DNA or RNA molecule has been sequenced.
- The resulting data is a series of short DNA or RNA sequences (known as “reads”) that can be assembled into a complete genome or transcriptome using specialized software. The assembled genome or transcriptome can then be analysed to identify genetic variations, study gene expression, or perform other types of analysis.
Types:
- Single-molecule sequencing: This approach involves sequentially reading the nucleotides of a single DNA molecule.
- Parallel sequencing: This approach involves sequencing many DNA molecules at the same time.
- Clonal amplification sequencing: This approach involves amplifying DNA molecules using the polymerase chain reaction (PCR) before sequencing.
- Hybridization-based sequencing: This approach involves hybridizing DNA molecules to a solid surface and then sequentially reading the nucleotides.
- Sequencing by synthesis: This approach involves synthesizing a DNA molecule using a template strand and reading the nucleotides as they are added.
- Ion semiconductor sequencing: This approach involves detecting ions produced during DNA synthesis and using them to determine the nucleotide sequence.
- Nanopore sequencing: This approach involves passing a single DNA molecule through a nanopore and measuring the electrical current changes as the nucleotides pass through the nanopore.
Methods:
There are several different methods of NGS, each with its own strengths and limitations. These are just a few examples of the many methods of NGS that are available. The choice of method depends on the specific research question and the type of data that is needed.
- Pyrosequencing: This method uses enzymes to synthesize DNA strands, and a light-sensitive molecule to detect the incorporation of individual nucleotides. Pyrosequencing is relatively fast and can produce high-quality data, but it is limited to short reads (sequences of up to about 400 bases) and is not as sensitive as some other methods.
- Illumina sequencing: This method uses short, complementary DNA strands (known as “sequencing by synthesis”) to synthesize longer DNA strands. Illumina sequencing is fast, accurate, and can generate very large amounts of data, but it is limited to relatively short reads (up to about 300 bases).
- Ion Torrent sequencing: This method uses a semiconductor chip to detect changes in pH as nucleotides are added to a DNA template. Ion Torrent sequencing is relatively fast and can produce high-quality data, but it is limited to shorter reads (up to about 400 bases) and requires specialized equipment.
Steps:
Sequencing data can be used for a variety of purposes, including the study of gene expression, the identification of genetic variations, the annotation of genomes, and the analysis of structural variations in the genome.
Sample preparation
This involves extracting DNA from the sample and preparing it for sequencing. The sample may be from a variety of sources, such as a blood sample, a tissue biopsy, or environmental samples.
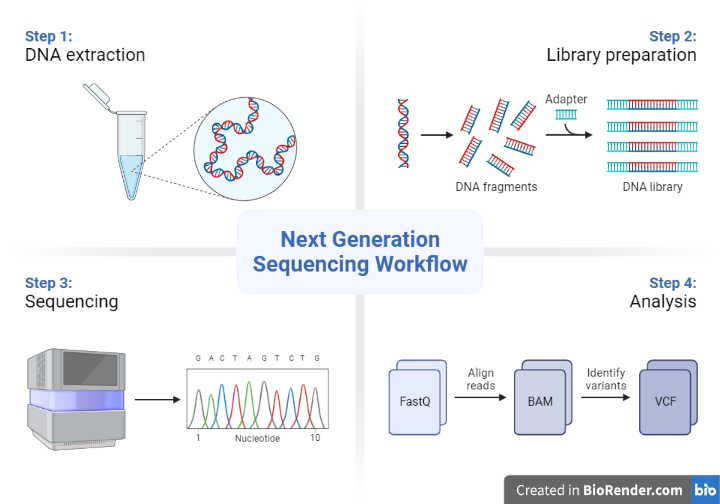
Fig: Next Generation Sequencing Workflow
Library construction
This involves fragmenting the DNA into smaller pieces and attaching adapters to the ends of the fragments. The adapters allow the fragments to be amplified and sequenced using the sequencing platform.
Sequencing
This involves using the sequencing platform to determine the sequence of the DNA fragments. There are several different types of sequencing technologies, including next-generation sequencing (NGS), Sanger sequencing, and others.
Data analysis
This involves using computer software to analyse the sequence data and generate results. The results may include the identification of genetic variations, the annotation of genes and regulatory elements, or the detection of structural variations.
Data Processing:
NGS data processing is typically done using specialized software tools that are designed to handle the large amounts of data generated by NGS experiments. These tools are often run-on high-performance computing clusters, which can process the data much faster than a single computer.
Next-generation sequencing (NGS) generates large amounts of data, which must be processed and analysed in order to extract meaningful information. The data processing steps for NGS data typically involve the following steps:
- Alignment: The first step in NGS data processing is to align the short sequence reads to a reference genome or transcriptome. This is typically done using specialized software tools, such as BWA or Bowtie.
- Consensus sequence generation: Once the reads have been aligned, a consensus sequence is generated, which represents the most likely sequence of the original DNA molecule.
- Variant calling: The aligned reads are then used to identify genetic variations, such as single nucleotide polymorphisms (SNPs) and small insertions and deletions (indels). This process is known as variant calling, and it is typically performed using specialized software tools such as GATK or Samtools.
- Quality control: Quality control involves checking the data for errors or biases, and may include steps such as removing low-quality reads or identifying and correcting for technical artifacts.
- Annotation: Annotation involves adding information about the function and location of the genes identified in the data. This may include identifying the gene and protein products encoded by the DNA sequence, as well as any regulatory elements or other functional elements.
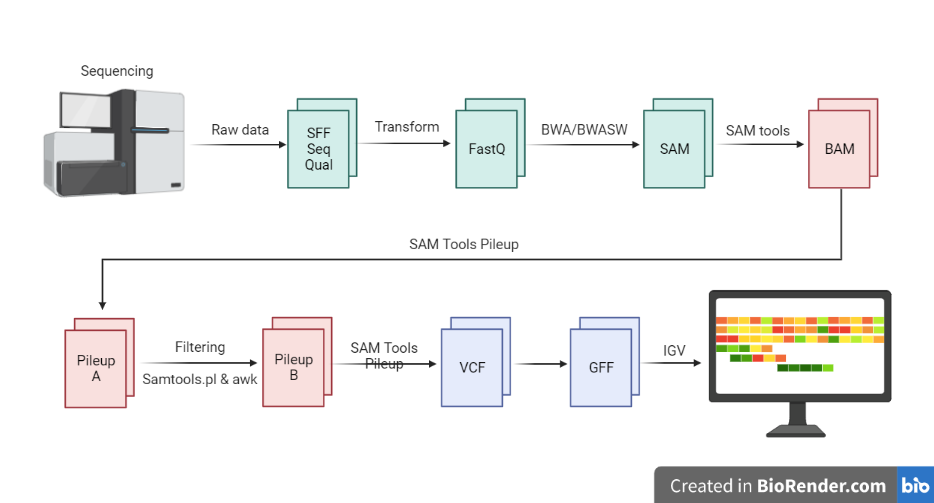
Fig: Next Generation Sequencing Data Processing
Applications:
Next-generation sequencing (NGS) is a powerful technology that has a wide range of applications in various fields.
- Genomics: NGS is used to sequence and analyze the genome of an organism, which can be used to study the genetic basis of various traits and diseases, and to identify genetic variations that may be associated with particular diseases or conditions.
- Transcriptomics: NGS is used to study the expression of genes in a particular tissue or cell type, which can help researchers understand how genes are regulated and how they interact with each other, as well as identify genes that are associated with particular biological processes or diseases.
- Epigenomics: NGS is used to study the chemical modifications that occur on DNA or histones (proteins around which DNA is wrapped), which can affect gene expression and play a role in development and disease.
- Metagenomics: NGS is used to study the genetic material present in a sample of mixed organisms, such as the microbes found in soil or the human microbiome, which can help researchers understand the roles that different microbes play in the environment or in the human body, and identify potential new therapies or treatments.
- Forensics: NGS can be used to identify individuals from DNA samples.
- Environmental studies: NGS can be used to study the diversity and distribution of microorganisms in different ecosystems.
Limitations:
- Cost: NGS can be expensive, especially for large projects or when multiple samples need to be analysed.
- Data analysis: NGS generates a large amount of data, which can be difficult to analysed and interpret. Specialized software and expertise are often required to analysed the data and extract meaningful information.
- Quality of samples: The quality of the samples being analysed can affect the accuracy and reliability of the results. Poor quality samples can lead to errors in the data or inaccurate conclusions.
- Depth of coverage: NGS can only provide information about the sequences that are present in the sample being analysed. If the sample is not representative of the entire genome or transcriptome, the results may not be accurate.
- Allele-specific expression: NGS can only provide information about the overall expression of a gene, rather than the expression of specific alleles (variants) of a gene.
- Genetic variations: NGS can identify genetic variations, but it may not be able to determine the functional consequences of those variations.
References:
- Behjati S, Tarpey PS. What is next generation sequencing? Arch Dis Child Educ Pract Ed. 2013 Dec;98(6):236-8.
- Gao, B., Chi, L., Zhu, Y., Shi, X., Tu, P., Li, B., Yin, J., Gao, N., Shen, W. and Schnabl, B., 2021. An introduction to next generation sequencing bioinformatic analysis in gut microbiome studies. Biomolecules, 11(4), p.530.
- Kumar KR, Cowley MJ, Davis RL. Next-Generation Sequencing and Emerging Technologies. Semin Thromb Hemost. 2019 Oct;45(7):661-673.
- Lohmann, K. and Klein, C., 2014. Next generation sequencing and the future of genetic diagnosis. Neurotherapeutics, 11(4), pp.699-707.
- Low, L. and Tammi, M., 2017. Introduction to next generation sequencing technologies. Bioinformatics: A Practical Handbook Of Next Generation Sequencing And Its Applications, p.1.